Let's explore how to use the Slurm Batch System to the ATOS HPCF or ECS.
Access the default login node of the ATOS HPCF or ECS.
Create a directory for this tutorial so all the exercises and outputs are contained inside:
mkdir ~/batch_tutorial cd ~/batch_tutorial |
Create and submit a job called simplest.sh with just default settings that runs the command hostname. Can you find the output and inspect it? Where did your job run?
Using your favourite editor, create a file called
You can submit it with sbatch:
The job should be run shortly. When finished, a new file called
You can then see that the script has run on a different node than the one you are on. If you repeat the operation, you may get your job to run on a different node every time, whichever happens to be free at the time. |
Configure your simplest.sh job to direct the output to simplest-<jobid>.out, the error to simplest-<jobid>.err both in the same directory, and the job name to just "simplest". Note you will need to use a special placeholder for the -<jobid>.
Using your favourite editor, open the
You can submit it again with:
After a few moments, you should see the new files appear in your directory (job id will be different than the one displayed here):
You can check that the job name was also changed in the end of job report:
|
From a terminal session outside the Atos HPCF or ECS your VDI or computer, submit the simplest.sh job remotely. What hostname should you use?
You must use hpc-batch for HPCF job submissions, or ecs-batch for remote submissions:
Note the change of directory so both the job script, the working directory of the job and its outputs are generated in the right place. An alternative way of doing this without changing directory would be to tell sbatch to do it for you:
or for ECS:
|
Create a new job script sleepy.sh with the contents below:
#!/bin/bash sleep 120 |
Submit sleepy.sh to the batch system and check its status. Once it is running, cancel it and inspect the output.
You can submit your job with:
You can then check the state of your job with squeue:
if you use the
to list all your jobs. To cancel your job, just run scancel:
If you inspect the output file from your last job, you will see a message like the following:
|
Can you get information about the jobs you have run so far today, including those that have finished already?
When jobs finish, they will not appear in the
With no arguments, this command will show you the list of all jobs run by you on this day. In the output you may see or more entries 3 entries such as:
The first one corresponds to the job itself. The second one (always named batch) corresponds to the actual job script and the third (named extern) corresponds to the external step used to generate the end of job information. You may have more lines if your job contains more steps, which typically correspond to srun parallel executions. If you want to list just the entry for the job itself, you can do:
|
Can you get information of all the jobs run today by you that were cancelled?
You can filter jobs by state with the -s option. But If you run it naively:
You will get no output. That is because when using state you must also specify the start and end times of your query period. You can then do something like:
|
The default information shown on the screen when querying past jobs is limited. Can you extract the submit, start, and end times of your cancelled jobs today? What about their output and error path? Hint: use the corresponding man page for all the options.
You can use the following command to see all the possible output fields you can query for:
While there are dedicated fields for the job submit, start and end times, there is none for the output and error paths. However, the AdminComment field is used to carry that information. Since it is a long field, you may want to pass a length to the fieldname to avoid truncation:
or you can also ask for a parsable output:
|
We will now attempt to troubleshoot some issues
Create a new job script broken1.sh with the contents below and try to submit the job. What happened? Can you fix the job and keep trying until it runs successfully?
#SBATCH --job-name = broken 1 #SBATCH --output = broken1-%J.out #SBATCH --error = broken1-%J.out #SBATCH --qos = express #SBATCH --time = 00:05:00 echo "I was broken!" |
The job above has the following problems:
Here is an amended version following best practices for the jobs:
Note that the QoS line was removed, but you may also use the following if running on ECS:
or the alternatively, if on Atos HPCF:
Check that the actual job run and generated the expected output:
|
Create a new job script broken2.sh with the contents below and try to submit the job. What happened? Can you fix the job and keep trying until it runs successfully?
#!/bin/bash #SBATCH --job-name=broken2 #SBATCH --output=broken2-%J.out #SBATCH --error=broken2-%J.out #SBATCH --qos=ns #SBATCH --time=10-00 echo "I was broken!" |
The job above has the following problems:
Here is an amended version:
Again, note that the QoS line was removed, but you may also use the following if running on ECS:
or the alternatively, if on Atos HPCF:
Check that the actual job run and generated the expected output:
|
Create a new job script broken3.sh with the contents below and try to submit the job. What happened? Can you fix the job and keep trying until it runs successfully?
#!/bin/bash #SBATCH --job-name=broken3 #SBATCH --chdir=$SCRATCH #SBATCH --output=broken3output/broken3-%J.out #SBATCH --error=broken3output/broken3-%J.out echo "I was broken!" |
The job above has the following problems:
You will need to create the output directory with:
Here is an amended version of the job:
Check that the actual job run and generated the expected output:
You may clean up the output directory with
|
Create a new job script broken4.sh with the contents below and try to submit the job. You should not see the message in the output. What happened? Can you fix the job and keep trying until it runs successfully?
#!/bin/bash #SBATCH --job-name=broken4 #SBATCH --output=broken4-%J.out ls $FOO/bar echo "I should not be here" |
The job above has the following problems:
Here is an amended version of the job following best practices:
With the extra shell options, we guarantee we get some extra information on the output about the commands being written, and we ensure that the job will stop when encountering the first error (non-zero exit code), as well as if an undefined variable is found.
|
Although most limits are described in HPC2020: Batch system, you can also check them (or reach them) for yourself in the system.
Create a new job script naughty.sh with the following contents:
#!/bin/bash #SBATCH --mem=100 #SBATCH --output=naughty.out MEM=300 perl -e "\$a='A'x($MEM*1024*1024/2);sleep 60" |
Submit naughty.sh to the batch system and check its status. What happened to the job?
You can submit it with:
You can then monitor the state of your job with squeue:
After a few seconds of running, you may see the job finishes and disappears. If we use sacct, we can see the job has failed, with an exit code of 9, which indicates it was killed:
Inspecting the job output the reason becomes apparent:
|
Edit naughty.sh to comment the request for memory, and then play with the MEM value.
#!/bin/bash #SBATCH --output=naughty.out ##SBATCH --mem=100 MEM=300 perl -e "\$a='A'x($MEM*1024*1024/2);sleep 60" |
How high can you with the default memory limit on the default QoS before the system kills it?
With trial and error, you will see the system will kill your tasks that go over 8000 MiB:
Inspecting the job output will confirm that:
|
How could you have checked this beforehand instead of taking the trial and error approach?
You could have checked HPC2020: Batch system, or you could also ask Slurm for this information. Default memory is defined per partition, so you can then do
The field we are looking for is
|
Can you check, without trial and error this time, what is the maximum wall clock time, maximum CPUs, and maximum memory you can request to Slurm for each QoS?
Again, you will find this information ini HPC2020: Batch system, but you can also ask Slurm. These settings are part of the QoS setup so the command is
The fields we are looking for this time are
If you run this on HPCF, you may notice there is no maximum limit set at the QoS level for the np parallel QoS, so you are bound by the maximum memory available in the node. You can also see other limits such as the local SSD tmpdir space. |
How many jobs could you potentially have running concurrently? How many jobs could you have in the system (pending or running), before a further submission fails?
Again, you will find this information ini HPC2020: Batch system, but you can also ask Slurm. These settings are part of the Association setup so the command is
The fields we are looking for are
Remember that a Slurm Association is made of the user, project account and partition, and the limits are set at the association level. |
So far we have only run serial jobs. You may also want to run small parallel jobs, either concurrently using just multiple threads, multiple processes or both. Examples of this are MPI and OpenMP programs. We call these kind of small parallel jobs "fractional", because they will run on a fraction of a node, sharing it with other users.
If you followed this tutorial so far, you will have realised ECS users may run very small parallel jobs on the default ef QoS, whereas HPCF users may run slightly bigger jobs (up to half a GPIL node) on the default nf QoS.
For this tests we will use David McKain's version of the Cray xthi code to visualise how the process and thread placement takes place.
Load the xthi module with:
module load xthi |
Run the program interactively to familiarise yourself with the ouptut:
$ xthi Host=ac6-200 MPI Rank=0 CPU=128 NUMA Node=0 CPU Affinity=0,128 |
As you can see, only 1 process and 1 thread are run, and they may run on one of two virtual cores assigned to my session (which correspond to the same physical CPU). If you try to run with 4 OpenMP threads, you will see they will effectively fight each other for those same two cores, impacting the performance of your application but not anyone else in the login node:
$ OMP_NUM_THREADS=4 xthi Host=ac6-200 MPI Rank=0 OMP Thread=0 CPU=128 NUMA Node=0 CPU Affinity=0,128 Host=ac6-200 MPI Rank=0 OMP Thread=1 CPU= 0 NUMA Node=0 CPU Affinity=0,128 Host=ac6-200 MPI Rank=0 OMP Thread=2 CPU=128 NUMA Node=0 CPU Affinity=0,128 Host=ac6-200 MPI Rank=0 OMP Thread=3 CPU= 0 NUMA Node=0 CPU Affinity=0,128 |
Create a new job script fractional.sh to run xthi with 2 MPI tasks and 2 OpenMP threads, submit it and check the output to ensure the right number of tasks and threads were spawned.
Here is a job template to start with:
#!/bin/bash
#SBATCH --output=fractional.out
# TODO: Add here the missing SBATCH directives for the relevant resources
# Define the number of OpenMP threads
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-1}
# Load xthi tool
module load xthi
# TODO: Add here the line to run xthi
# Hint: use srun
|
Using your favourite editor, create a file called
You need to request 2 tasks, and 2 cpus per task in the job. Then we will use srun to spawn our parallel run, which should inherit the job geometry requested, except the You can submit it with sbatch:
The job should be run shortly. When finished, a new file called
You should see an output similar to:
|
Can you ensure each one of the OpenMP threads runs on a single physical core, without exploiting the hyperthreading, for optimal performance?
In order to ensure each thread gets their own core, you can use the environment variable Then, to make sure only physical cores are used for performance, we need to use the
You can submit the modified job with sbatch:
You should see an output similar to the following one, where each thread is in a different core with a number lower than 128:
|
For bigger parallel executions, you will need to use the HPCF's parallel QoS, np, which gives access to the biggest partition of nodes in every complex.
When running in such configuration, your job will get exclusive use of the nodes where it will run so external interferences are minimised. It is important then that the resources allocated are used efficiently.
Here is a very simplified diagram of the Atos HPCF node that you should keep in mind when deciding your job geometries:
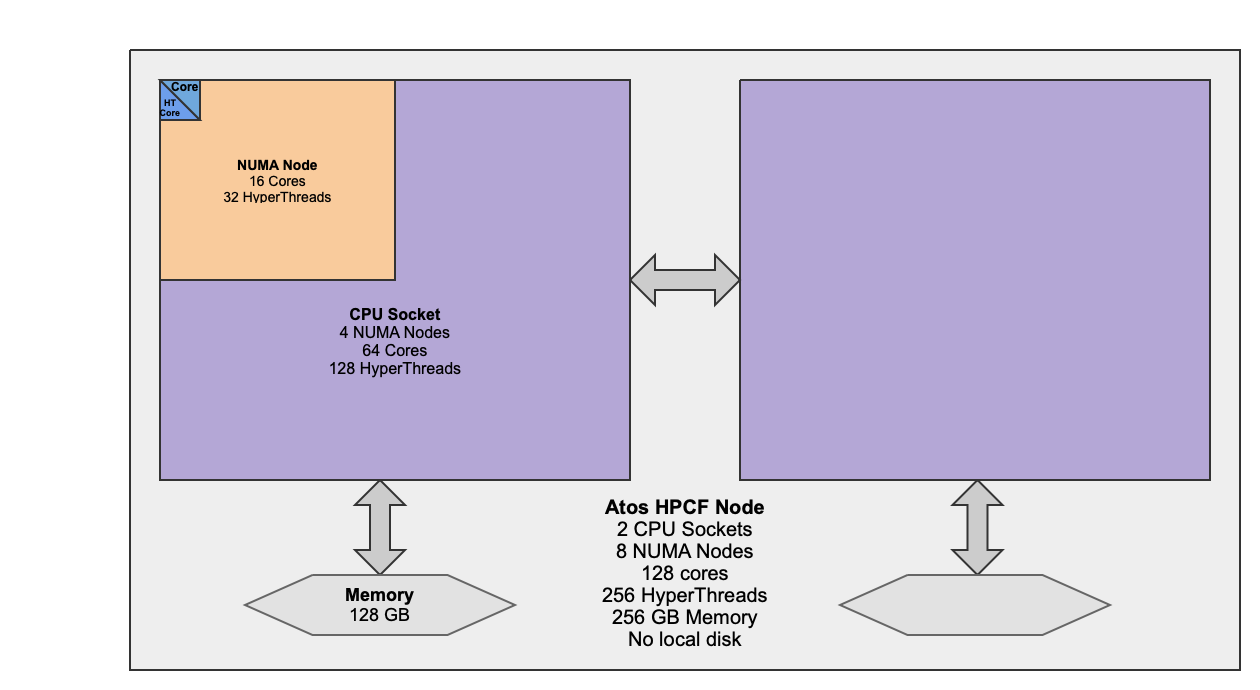
hpc-login.Create a new job script parallel.sh to run xthi with 32 MPI tasks and 4 OpenMP threads, leaving hyperthreading enabled. Submit it and check the output to ensure the right number of tasks and threads were spawned. Take note of what cpus are used, and how much SBUs you used.
Here is a job template to start with:
#!/bin/bash
#SBATCH --output=parallel-%j.out
#SBATCH --qos=np
# TODO: Add here the missing SBATCH directives for the relevant resources
# Define the number of OpenMP threads
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-1}
# Ensure proper OpenMP thread CPU pinning
export OMP_PLACES=threads
# Load xthi tool
module load xthi
srun -c $SLURM_CPUS_PER_TASK xthi |
Using your favourite editor, create a file called parallel
You need to request 32 tasks, and 4 cpus per task in the job. Then we will use srun to spawn our parallel run, which should inherit the job geometry requested, except the You can submit it with sbatch:
The job should be run shortly. When finished, a new file called
You should see an output similar to:
Note the following facts:
In terms of SBUs, this job cost:
|
Modify the parallel.sh job geometry (number of tasks, threads and use of hyperthreading) so that you fully utilise all the physical cores, and only those, i.e. 0-127.
Without using hyperthreading, an Atos HPCF node has 128 phyisical cores available. Any combination of tasks and threads that adds up to that figure will fill the node. Examples include 32 tasks x 4 threads, 64 tasks x 2 threads or 128 single-threaded tasks. For this example, we picked the first one:
You can submit it with sbatch:
The job should be run shortly. When finished, a new file called
You should see an output similar to:
Note the following facts:
In terms of SBUs, this job cost:
|
Modify the parallel.sh job geometry so it still runs on the np QoS, but only with 2 tasks and 2 threads. Check the SBU cost. Since the execution is 32 times smaller, did it cost 32 times less than the previous? Why?
Let's use the following job:
You can submit it with sbatch:
The job should be run shortly. When finished, a new file called
You should see an output similar to:
In terms of SBUs, this job cost:
This is in a similar scale to the previous one which 32 times bigger one. The reason behind it is that on the np QoS the allocation is done in full nodes. The SBU cost takes into account the allocated nodes for a given period of time, no matter how they are used. You may compare the cost of your last parallel job and your last fractional, with the same geometry (2x2):
|